

Why Three Sensors, Not Two
The best architectures don't just detect failures, they absorb them

Reliability engineering is often defined as:
a sub-discipline of systems engineering that emphasizes the ability of equipment to function without failure.
This framing relegates it to a specialty. A box to check. A task for a dedicated team. But reliability engineering is just engineering.
It’s the entire point.
Complex systems operate with razor-thin margins, under demanding conditions, and for extended durations. They’re also designed under considerable uncertainty. This creates thousands of ways to fail.
Good designs are able to both avoid failure modes and tolerate them. Reliability means the part works. Redundancy means there’s an alternative if it doesn’t. Working these concepts directly into a system’s architecture can make it inherently trustworthy.
This series of As Built essays is about doing just that. We’ll explore a variety of approaches and architectures that enhance system confidence. The end product will be a menu of tried-and-true methods that can be adapted to any design.

Most operational systems carry a myriad of sensors. Some of these are engineering sensors to characterize performance and improve the design. Others are control sensors that the system actually uses to make decisions.
If a control sensor fails, it could end the mission. So we rarely rely on just one.
Are two better than one?
Consider the embarkation door on a cruise ship. It is relatively low on the hull, and passengers board through it at the dock. When the ship is at sea, this door must be sealed to protect from large waves.


The door has a contact switch that gives a binary reading: open or closed. The captain relies on this data to keep the ship safe. But what if the sensor fails?
We could add a second contact switch to achieve dual modular redundancy. On its surface, we've solved the problem—now we have a backup. If one switch completely fails and stops sending data, we could trust the remaining sensor.
But this architecture has limits. But what if one sensor reads open and the other says closed? Which do we believe?
While dual modular redundancy provides a backup if one sensor fails, it doesn’t enable error correction. If the two sensors contradict, the captain faces a difficult situation.
Three voters
By adding a third contact switch, we can accommodate contradiction through majority voting. Each sensor casts a vote: open or closed. A voting apparatus tallies these votes and outputs the majority value.
If two sensors read closed, but one reads open, then the voting system will output that the door is closed. Today, this is typically a small piece of software, but for Boolean values, it can also be created with analog circuits.
This is a triple-modular-redundant system, and it allows us to be one fault tolerant. In other words, one of the three sensors can fail, and we can still function normally.
For our ship door, this arrangement works well. But what if the data streams were more complicated than just open or closed?
Non-Boolean values
Let's consider another part of the ship: the steering system. As the vessel navigates the Pacific, it uses hydraulic rams to turn the rudder. The rudder weighs 100 tons and encounters significant hydrodynamic pressure as it turns. To overcome these loads, the piston rams are powered by hydraulic fluid at 2000 psi.

Unlike the door contact switch, there are two failure modes here: low and high. If the hydraulic pressure is low, the system can’t steer the ship. If the pressure is high, the system bursts.
Therefore, the captain must have an accurate understanding of the hydraulic pressure, which we collect with three redundant pressure sensors.
Our triple modular redundancy voting system works, but requires slightly more logic. Assume we have three pressure sensors. Our algorithm would be:
First, establish which two sensors are in closer agreement.
Second, take the average of the two sensors in close agreement.
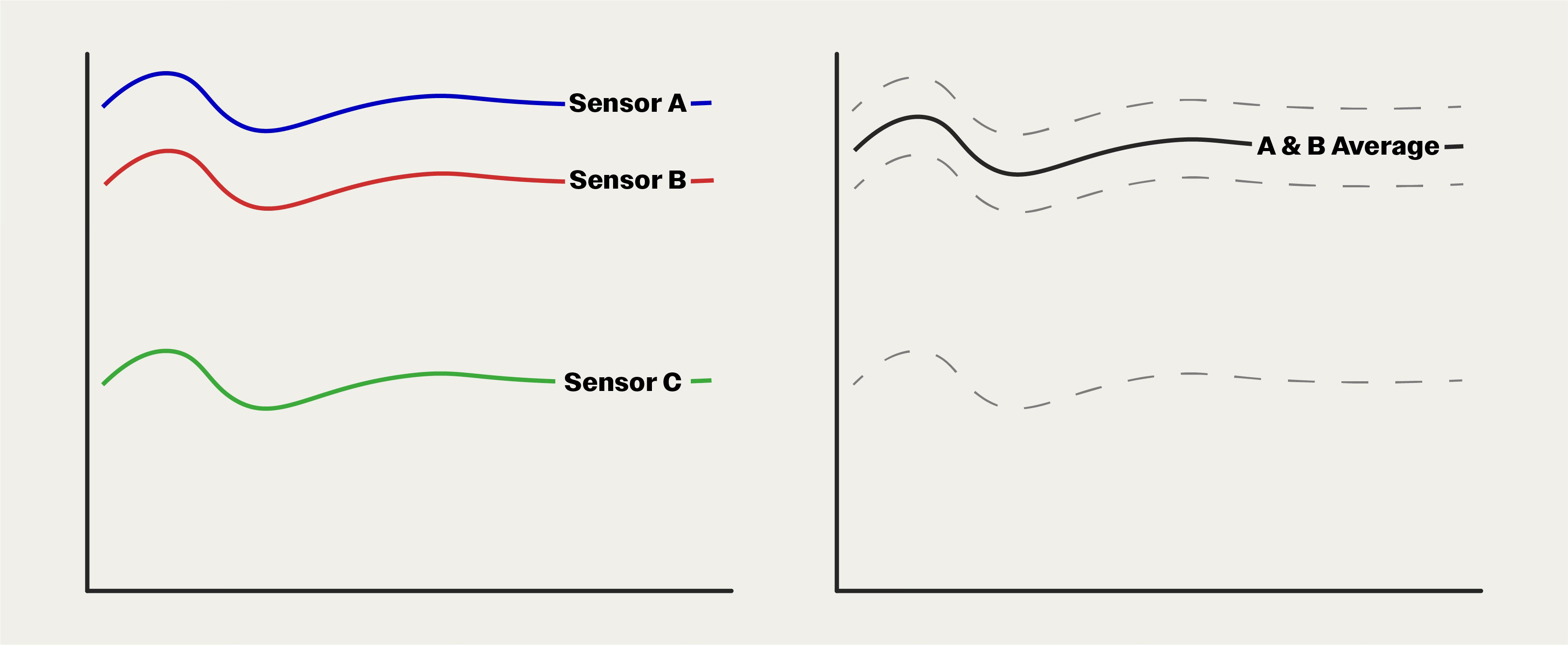
For non-Boolean values, we need this second averaging step to address the variance between the two sensors that agree. They won’t read the exact same value due to calibrations, sensor drift, and general uncertainty. To achieve precision, we take the average.
Can it be simpler?
The frameworks listed so far achieve single fault tolerance, but require the sensor layer, the voting layer, and, for non-Boolean values, the final averaging action.
We can simplify by taking the median.
Consider the three hydraulic pressure sensors. Instead of voting, we read all three data streams and at each sample point, take the median. The composite median time series is displayed to the ship captain.
The beauty of this arrangement is how it passively handles a variety of fault conditions.
During nominal operation, we'd expect to see three pressure traces, tightly grouped. In this example, Sensor B is in the middle and is therefore reported as the median value.
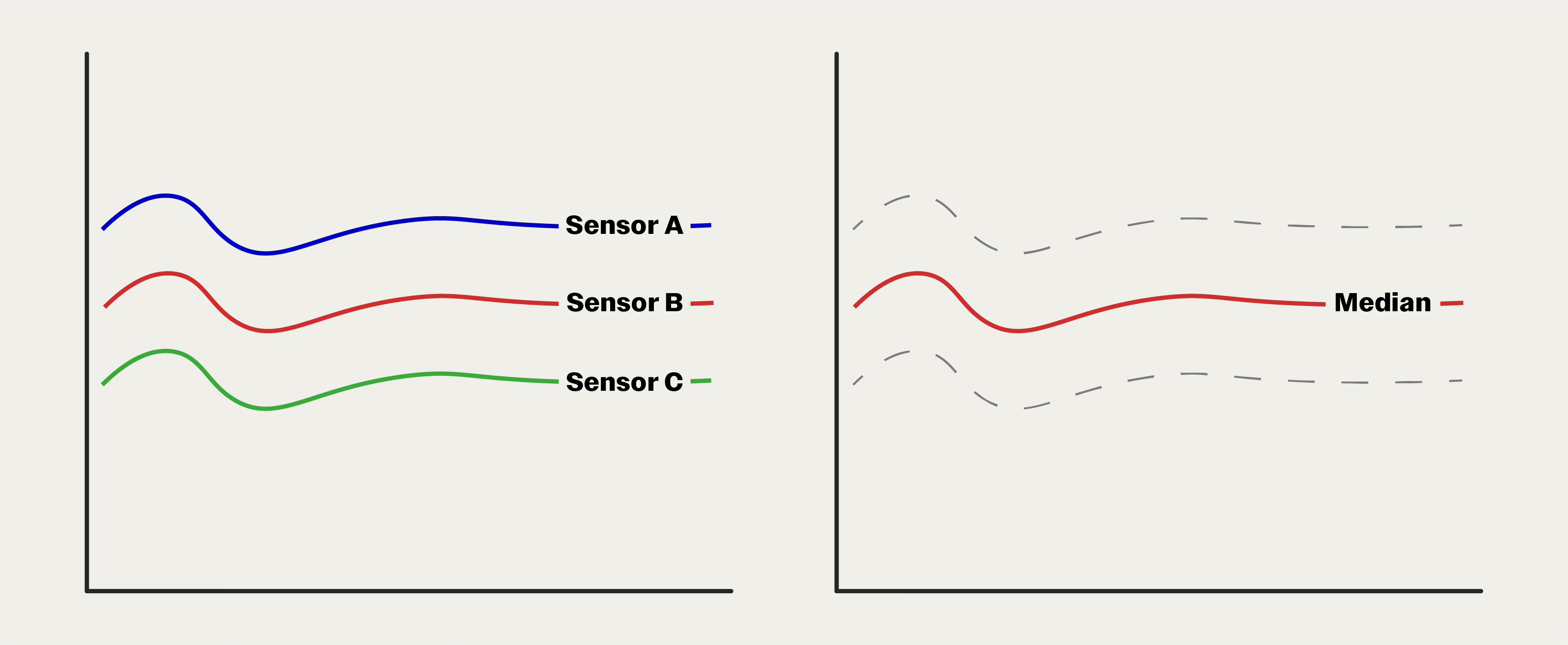
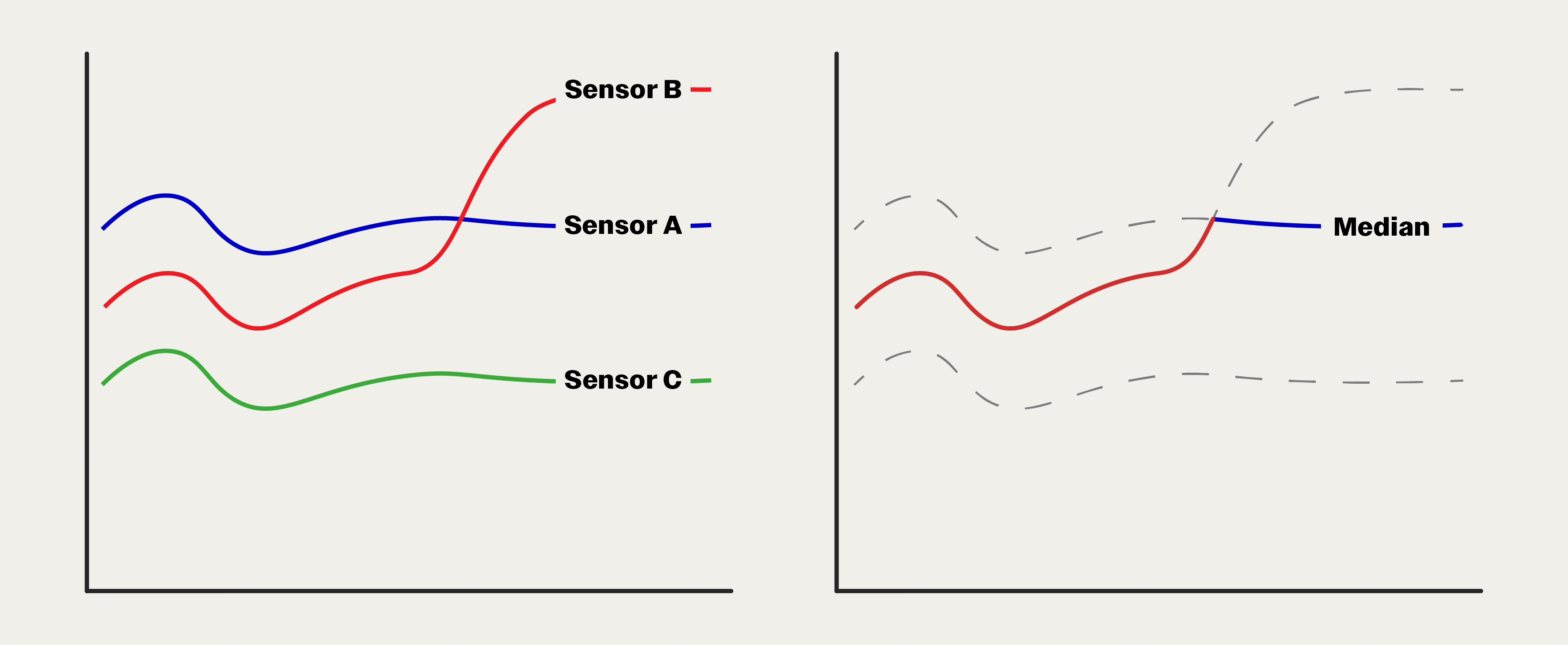
However, maybe an exhaust leak starts to cause Sensor B to heat up. This results in the sensor drifting upward and taking a 200 psi offset. In this case, the median is Sensor B until it crosses above Sensor A, then Sensor A data is reported as the median. All of this happens automatically and transparently to the ship captain.
This arrangement also accommodates failed sensors. Maybe a big wave rocks the ship and breaks the wires to Sensor B, causing it to drop to 0 psi. The system seamlessly responds to now report Sensor C as the median.
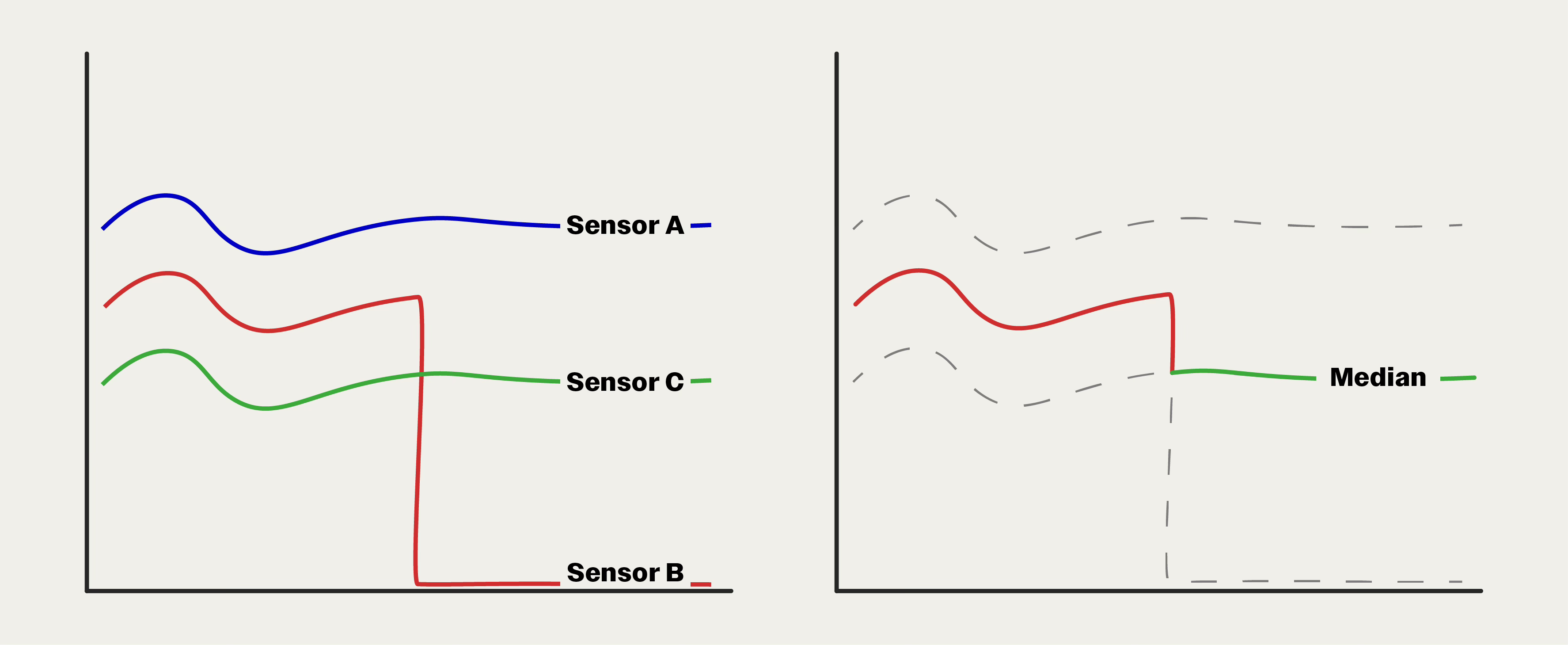
In this setup, we don’t require voting or averaging. We simply always take the median of our three sensors, and in doing so, remain single fault tolerant. The best architectures don't detect failures. They absorb them.
Flagging faults
While the median operating system seamlessly handles failures, the issues still need to be reported to the ship captain. If we’re single fault tolerant and we’ve taken a fault, we can’t take another one.
It can be helpful to act on the median and flag any sensor that deviates from it. In the hydraulic pressure case, perhaps the system flags if any one pressure is more than 50 psi away from the median.
With this insight, the captain can take an action. This might be going down to repair the sensor, operating the ship more cautiously, or even returning to port.
Common mode failures
These setups all protect against one fault. We can architect systems to accommodate multiple faults by adding sensors and logic, but the effort can yield diminishing returns and increased complexity.
Common mode failures are also a consideration. This would be an event that damages more than one sensor. Maybe that exhaust leak in the engine compartment heats all three sensors, causing them to all drift high and trigger a false alarm.
For this reason, sometimes it’s beneficial to separate the sensors, moving them physically apart or routing the wire harnessing along different paths so it’s less likely that all get impacted by the same event.
Tying it all together
The most basic aspect of reliability is getting good data, and I’ve always viewed the triplicated median approach as one of the most elegant ways to do so.
The next part of this series will step up a level from sensors to networks. We’ll look at network redundancy and how to manage failovers when a component hits an issue.
In nearly every case study, we’ll see the same thing. Simplicity always wins—the fewer systems, the fewer possible failures. The simpler the logic, the easier it is to prove every case will work. And that’s the entire point.

Brillant breakdown of TMR. The median apprach really is elegant because it handles sensor drift and hard failurs witout needing separate votng logic. I've seen avionics teams stick with traditonal voting systems when median selection would simplify everything and reduce points of failure.
Thanks Harry, great post, really interesting finding out about triple modular redundancy and how you can use this in such practical ways. I never really thought about how a captain knows if the cruise ship boarding door is shut or not but now I know, thank you!